
Agent evaluation systems are where AI governance stops asking whether a model call was allowed and starts asking whether autonomous behavior remains acceptable over time.
A financial institution can have clear identity, traceable lineage, stable semantics, and a well-governed AI gateway and still fail at the next point that matters: ongoing performance.
If an agent is allowed to act but no system measures whether it is accurate, bounded, reliable, and consistent with policy in production, the architecture may be controlled. It is not yet governed at the level of autonomy.
That is why agent evaluation systems matter.
They are often described as testing suites, benchmark dashboards, or model-quality tooling. That is useful. It is not enough for governance.
In regulated financial environments, agent evaluation systems are the layer that determines whether an autonomous system is performing within acceptable bounds, when human review has to be inserted, when capabilities have to be constrained, and what evidence exists to defend continued deployment.
By this point in the series, model access is already controlled.
Identity establishes what exists and who is acting. Lineage establishes what can be trusted. Semantics establishes what things mean. Gateways establish whether a model call is allowed to happen at all.
That makes the system controllable at the point of access.
This is the next layer in the governance stack. Governance establishes authority. Metadata makes systems machine-operable. Identity resolves actors and artifacts. Lineage connects execution to evidence. Semantics stabilizes meaning. Gateways control model access. Agent evaluation determines whether autonomous behavior remains acceptable after access has been granted.
That is the shift from control to accountability.
Without agent evaluation, the earlier layers can authorize behavior.
With agent evaluation, the institution can judge whether authorized behavior should continue.
Previously in the Series
This article builds directly on the earlier layers of the AI governance stack:
- Why Governance is the Precondition for Scalable AI Agents
- Metadata for AI Agents vs. Human Metadata
- Identity for AI Systems: The Glue That Holds AI Governance Together
- Data Lineage as the Backbone of AI Governance
- Semantic Layers: The Hidden Infrastructure Behind Scalable AI
- AI Gateways: The Control Plane for Model Access
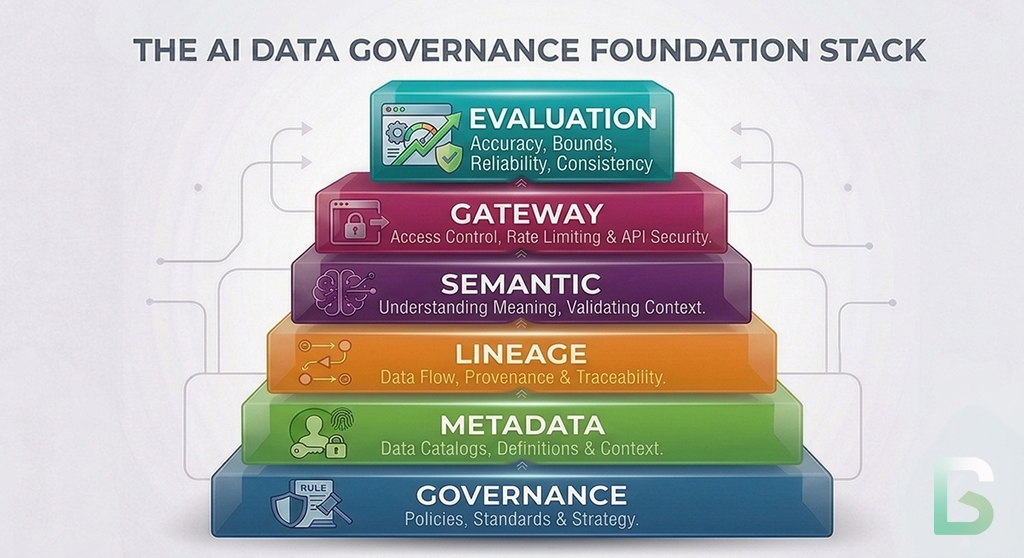
Why Gateway Control Is Not Enough
An approved action can still be the wrong action.
A gateway can block unapproved model use. It cannot by itself prove that an approved agent is behaving well.
Financial institutions feel this quickly when agentic use cases move from draft assistance into operational workflows. A customer-service agent may be approved to draft responses. A fraud assistant may be approved to summarize case context. A servicing agent may be allowed to recommend next steps. Access control answers whether those calls may happen. It does not answer whether the resulting behavior is accurate, stable, and safe enough to keep using.
- retrieve the wrong evidence
- over-trust stale or incomplete context
- escalate too little or too much
- produce outputs that look plausible but do not support the intended business action
- degrade after model, prompt, tool, or data changes
That is not a gateway failure.
It is a performance-governance problem.
Why Point-In-Time Testing Breaks Governance
Static benchmarks do not govern live autonomy.
Most organizations begin with pilot testing. They run prompts against curated examples, review outputs manually, and approve deployment when the results look strong.
That is necessary.
It is not enough.
Autonomous systems change in production even when the application code looks stable. Models are updated. Retrieval corpora drift. Upstream data quality shifts. Tool interfaces change. User behavior changes. Use cases expand beyond the narrow path originally tested.
What passed last month may be weak today.
That is one reason the practical evaluation guidance in Anthropic’s Demystifying evals for AI agents is useful here. It makes the same operational point from a product-engineering angle: without evals, teams fall into reactive loops, discover regressions late, and struggle to distinguish real performance changes from noise.
This is already familiar in financial model risk management. SR 11-7: Guidance on Model Risk Management states that validation activities should continue on an ongoing basis after a model goes into use and specifically calls for ongoing monitoring and outcomes analysis. Agent evaluation extends that same discipline into autonomous AI behavior, where the system may reason, retrieve, call tools, and generate actions across changing conditions.
That creates three governance failures when evaluation is weak.
No Definition Of Acceptable Autonomous Behavior
If no thresholds exist for task success, escalation quality, policy adherence, or outcome quality, the institution cannot say what working actually means.
No Systematic Detection Of Degradation
Teams may notice incidents. They may not detect slower, quieter failure patterns such as rising false escalations, lower retrieval precision, or uneven performance across products, channels, or customer segments.
No Trigger For Intervention
Even when degradation is visible, many firms have no defined rule for what happens next. Does autonomy get reduced? Is human review inserted? Does the capability get paused? Without evaluation-linked triggers, oversight remains ad hoc.
What An Evaluation System Actually Does
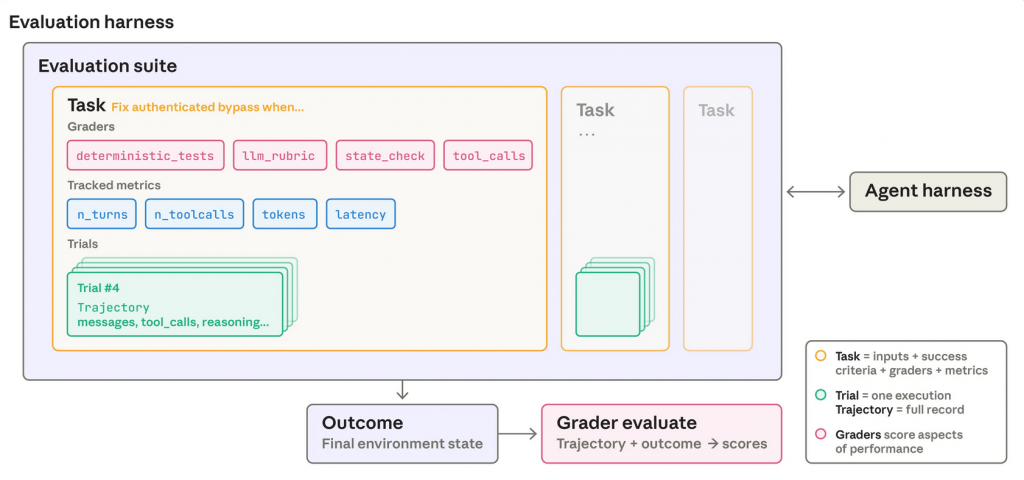
An agent evaluation system is not a leaderboard. It is the evidence layer for autonomous performance.
The common framing is too small.
An agent evaluation system does not merely score a model on generic benchmarks. In a governed architecture, it measures whether a specific agent or model-driven workflow is performing acceptably for a specific task, within a specific control environment, over time.
Its role is to determine what good performance means, measure whether the system is meeting that standard, detect when it stops doing so, and produce evidence that can support continued use, restriction, or redesign.
That makes evaluation governance-critical infrastructure.
The NIST AI Risk Management Framework treats measurement and management as core risk functions, not optional quality checks. For financial institutions, the implication is direct: autonomous systems need explicit measurement, thresholds, and intervention logic after deployment, not just before it.
Anthropic’s Demystifying evals for AI agents is also a strong implementation reference because it breaks evaluation into tasks, trials, graders, transcripts, and outcomes. That decomposition is useful for governance teams because it turns a vague requirement to “test the agent” into specific evidence-producing components.
The Capabilities That Matter
Good agent evaluation systems measure behavior before deployment, in production, and at change boundaries.
Use-Case-Specific Test Coverage
Generic benchmark scores do not tell a bank whether an agent handles disputes correctly, escalates suspicious activity appropriately, or stays within approved language for customer communications. Evaluation has to be tied to the real tasks the institution cares about.
Risk-Aligned Scoring And Thresholds
Not every failure has the same consequence. A summarization assistant and an action-enabling servicing agent should not be governed by the same thresholds. Evaluation should reflect materiality, downstream actionability, and business impact.
Tool-Use And Workflow Evaluation
Agents fail not only in final answers but in how they use tools. They may query the wrong system, call tools in the wrong sequence, omit evidence, or continue when they should escalate. Governance requires evaluating the execution path, not just the surface text.
Ongoing Monitoring And Outcomes Analysis
Predeployment evaluation is only the starting point. Institutions need recurring production sampling, drift detection, segmentation analysis, and comparison between predicted quality and observed outcomes.
The Anthropic agent evaluation piece is especially useful on operating mechanics because it distinguishes capability evals from regression evals and argues that transcript review remains necessary even when automated grading exists. That is directly relevant in finance, where firms need both a stable control threshold and a disciplined way to inspect why an agent passed or failed.
The Swiss Cheese Model from safety engineering is a useful analogy here. No single evaluation layer catches every issue. Automated evals miss some real-world failure modes. Production monitoring is grounded in live conditions, but it is reactive. Human review adds judgment, but it is selective and expensive. When those methods are combined, failures that slip through one layer are more likely to be caught by another.
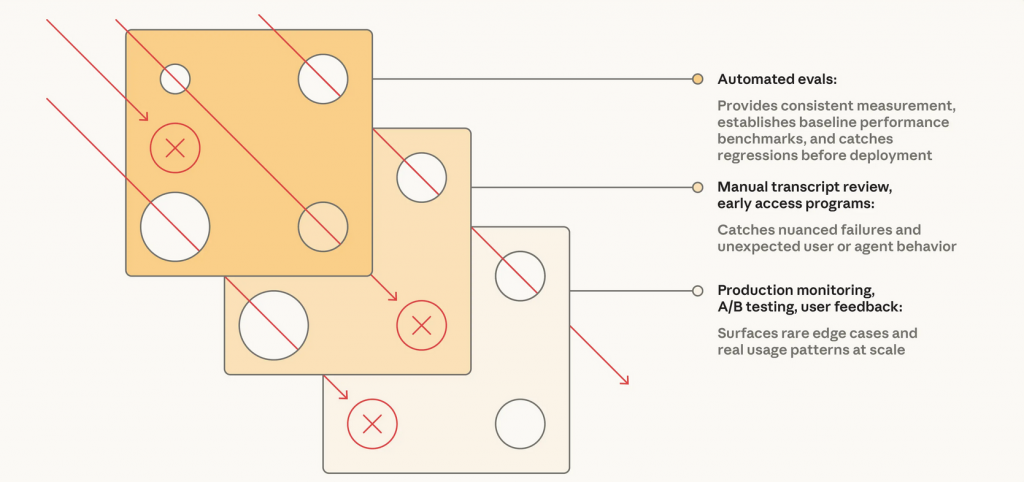
That is why the strongest operating model combines automated evals for fast iteration, production monitoring for ground truth, and periodic human review for calibration.
Furthermore, the NIST Generative AI Profile treats generative AI risk as something that has to be managed through context-specific controls rather than assumed away at deployment time.
Evaluation systems are one of the practical mechanisms by which that ongoing control is applied.
Human Review And Escalation Triggers
Evaluation is only useful if poor results change the operating mode. Threshold breaches should trigger defined actions such as recommendation-only mode, expanded review, rollback, or case-type restrictions.
Evidence That Connects To Lineage
Evaluation results should not live in isolated dashboards. They should connect to the system’s broader evidence chain: which model, prompt, tool set, policy configuration, dataset snapshot, and deployment version were being used when performance was measured.
At that point, evaluation is not just inspection.
It becomes governable performance evidence.
How Evaluation Closes The Loop
This is where allowed behavior is tested against acceptable behavior.
Evaluation is not independent of the rest of the architecture.
Identity tells the institution which agent, user, service, or delegated context produced the behavior being measured.
Lineage tells the institution how the execution path and downstream consequences can be reconstructed.
Semantics tells the institution whether the task, labels, policies, and success criteria are defined consistently.
Gateways tell the institution whether the call was allowed to happen.
Evaluation tells the institution whether continued autonomous behavior remains acceptable.
That is the conceptual shift that matters.
Evaluation translates task evidence into confidence.
It translates thresholds into oversight.
It translates degradation into intervention.
Where Oversight Actually Starts
Autonomy is only governable when poor performance changes what the system is allowed to do next.
Once an evaluation system sits inside the operating model, it can support real oversight:
- downgrade an agent from action-enabling to recommendation-only when task-quality scores fall below threshold
- require human review when escalation accuracy or policy adherence deteriorates in sensitive workflows
- pause or roll back a deployment when a model, prompt, or tool change causes measurable regression
- segment evaluation results by product, region, channel, or customer cohort to detect uneven failure patterns
- block expansion into new use cases until coverage, thresholds, and review logic exist
This is the practical difference between autonomy that is merely enabled and autonomy that is governed.
Without evaluation, institutions mostly discover performance failure after the damage is done.
With evaluation, they can constrain or redesign behavior before failure becomes systemic.
What Good Looks Like
The test is whether the institution can measure autonomous performance centrally and intervene before failure compounds.
A Fraud Operations Example
Consider a fraud operations assistant that gathers case context, summarizes suspicious activity, recommends investigation steps, and proposes whether a case should be escalated.
In a weak architecture, the assistant uses approved model access through a gateway and every call is logged. That is better than direct model use. It still does not tell the institution whether the assistant is retrieving the right evidence, applying the right escalation logic, or degrading when transaction patterns change. Analysts may sense that the tool is becoming less reliable, but the organization lacks a defined measurement system, threshold structure, or intervention path.
Identity may tell the institution which analyst or service invoked the assistant.
Lineage may capture what data and tools were used.
Semantics may define what a suspicious event, escalation, or disposition means.
The gateway may ensure the right model path was used.
That still does not mean the institution has governed autonomous behavior.
In a stronger architecture, the assistant is evaluated against use-case-specific tests and recurring production samples. The institution measures retrieval quality, escalation precision, case-summary accuracy, policy adherence, and downstream analyst override rates. Thresholds are segmented by case type and risk level. If performance degrades, the assistant is constrained to recommendation-only mode, routed to expanded human review, or rolled back pending remediation. Agent evaluation results are recorded as evidence alongside the deployment context and lineage trail.
At that point, the institution is not just allowing autonomy.
It is supervising it.
The Real Standard
You cannot supervise what you do not evaluate.
Agent evaluation systems matter because they change governance from one-time approval into ongoing accountability.
They are not optional benchmark dashboards. They are the mechanism by which institutions determine whether autonomous behavior remains acceptable in practice.
That is the standard that matters in financial services.
It supports model risk management, operational resilience, change governance, second-line oversight, incident response, and regulator engagement.
An organization that controls model access still does not have governed AI if it cannot measure whether agent behavior remains within acceptable bounds over time.
It has an access layer with weak performance governance.
Agent evaluation systems are where autonomy becomes accountable.
What Comes Next
Measuring behavior is necessary, but institutions also need a way to turn governance logic into executable decisions.
Once institutions can measure whether autonomous behavior is acceptable, the next question changes.
It is no longer only whether the system is performing well enough.
It is how thresholds, exceptions, approvals, and restrictions are translated into consistent operational decisions across workflows.
That is where policy engines come in.
Identity establishes who is acting.
Lineage establishes what can be trusted.
Semantics establishes what things mean.
Gateways establish what is allowed to happen.
Evaluation establishes whether behavior remains acceptable.
Policy engines determine how governance decisions are executed consistently at scale.
The next article will move from performance evidence to decision automation: how institutions encode governance logic, automate approvals and restrictions, and make policy executable across agent systems.
Series: The Architecture of Governed AI Systems
- Governance is the Precondition for Scalable AI Agents
- Metadata for AI Agents vs Human Metadata
- Identity for AI Systems: The Missing Layer of AI Governance
- Data Lineage as the Trust Backbone of AI Systems
- Semantic Layers: The Hidden Infrastructure Behind Scalable AI
- AI Gateways: The Control Plane for Model Access
- How to Evaluate AI Agents: Building a Governance Framework
- AI Policy Engines: How to Operationalize AI Governance for Financial Institutions
- Institutional Traceability: The Operating System of AI Governance (coming next)
Follow the Series
We are continuing to explore the architecture required for governed AI systems. Upcoming articles will cover identity infrastructure, policy engines, and AI control planes.
Subscribe to the Data Sense newsletter to receive updates when the next article is published.
