
Institutional Traceability for Scalable AI Agents
From Conversational Systems to Operational Actors
Scalable AI agents are quickly moving from experimental tools to embedded components of enterprise infrastructure. In financial services, manufacturing, retail, and other regulated sectors, autonomous systems are beginning to interface directly with ledgers, operational databases, and reporting pipelines. As these systems evolve from conversational assistants into operational actors capable of invoking tools, modifying records, and influencing downstream decisions, their risk profile changes materially.
As explored in our article on AI agents in data analytics, these systems can automate everything from data ingestion to predictive insights.
Why Traceability Becomes a Governance Requirement
At this stage, AI agent performance alone is no longer the central concern. The more consequential question is whether the institution can maintain traceability across the full lifecycle of agent activity. Each invocation, data transformation, and system update must be attributable in order to preserve accuracy and accountability. When orchestration cannot be reconstructed, oversight becomes speculative and auditability weakens in regulated environments.
This gap between technical capability and institutional traceability helps explain why large-scale deployment of AI agents continues to lag behind model innovation.
The Production Gap Is Structural, Not Technical
Evidence from MIT’s Project NANDA Report
MIT’s Project NANDA 2025 Report estimates that only a small fraction of AI initiatives reach meaningful production scale. While the exact percentage is less important than the pattern, the signal is clear: experimentation is widespread, institutional deployment is constrained.
This dynamic is frequently attributed to skills shortages or immature tooling. In practice, the limiting factor is structural readiness.
Correlated Risk Surfaces in Agentic Systems
Autonomous agents introduce correlated layers of exposure. Model uncertainty interacts with data integrity risk; operational dependency intersects with regulatory accountability. When an agent misclassifies, misroutes, or misexecutes, the impact does not remain localized. It can propagate into financial statements, compliance reporting, operational workflows, or customer-facing systems.
The Institutional Readiness Problem
Executives are not resisting autonomy because it lacks capability. They are hesitating because the control environment required to supervise it has not yet been fully constructed.
Governance as Operational Infrastructure
Governance for enterprise AI agents is often framed as a compliance overlay. In reality, it functions as operational infrastructure.
Autonomous systems require structured traceability across data inputs, transformation logic, tool invocation, output destinations, and human escalation points.
Without governance and standards, automated systems can quickly produce inconsistent or untrustworthy outputs. Similar issues have emerged in the democratization of data visualization, where access without oversight can create fragmented interpretations and data risks.
Traceability Requirements Under Emerging AI Regulation
Under regulatory regimes such as the EU AI Act and the AI Risk Management Framework developed by the National Institute of Standards and Technology, institutions must be able to demonstrate not only what a system produced, but how and why it produced it.
The Identifier Discipline Problem
This requirement exposes a foundational weakness in many organizations: insufficient identifier discipline.
Traceability for Scalable AI Agents: The Identifier Layer
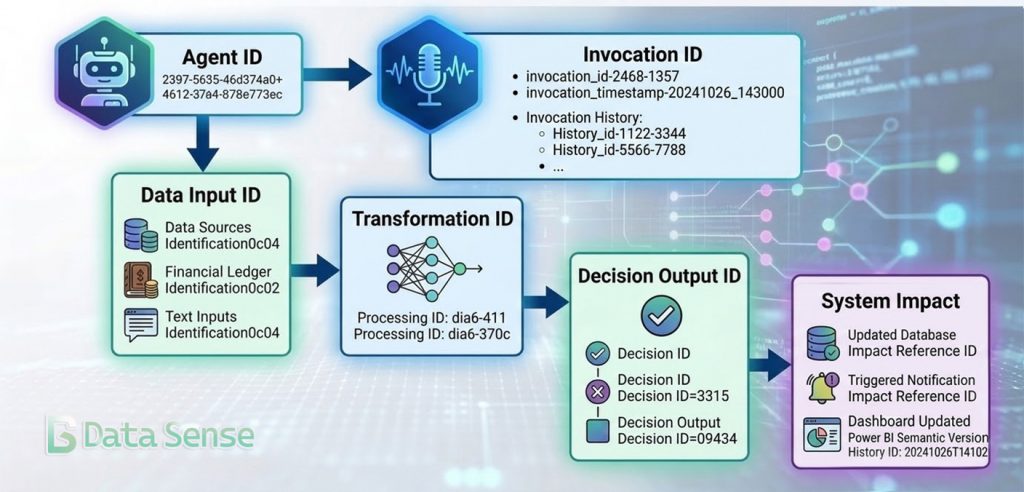
Scalable AI agents depend on a traceable chain of identifiers. Identifiers provide the linking mechanism that allows actions, data, and outputs to be reconstructed across distributed systems.
Identifier Architecture for Scalable AI Agents
Every autonomous action should be attributable across four dimensions:
- Agent Identity — Which specific agent instance executed the action?
- Invocation ID — Which execution of the agent produced the decision?
- Data Provenance — Which inputs, versions, and sources were accessed?
- Decision Output Lineage — Which systems, reports, or transactions were affected?
Together, these identifiers create a reconstructable execution path for every autonomous action. In practice, the structure resembles transaction tracing in distributed systems where each agent execution becomes a traceable event with defined inputs, processing context, and downstream effects.
Dataset-Level Provenance in Practice
For example, a reconciliation agent interacting with financial ledgers might reference a dataset snapshot such as:
DATASET:FIN_RECON_LEDGER:2026-03-05T10:42:18Z:v3
This identifier links the agent’s decision to a specific version of the underlying data, allowing investigators or auditors to reconstruct the precise input conditions that informed the output.
AI agents increasingly operate on top of automated data pipelines, where transformation steps, models, and reporting layers are orchestrated programmatically. These automation frameworks are already delivering measurable operational benefits across financial data workflows, as we explored in our analysis of financial data automation ROI.
Without persistent identifiers across these layers, system behavior cannot be reliably reconstructed. In regulated environments, where accountability depends on verifiable records, retrospective reconstruction becomes unreliable.
Financial markets confronted a similar challenge decades ago. Standardized identifiers for entities, instruments, and transactions were introduced precisely to reduce opacity and systemic fragility. Similar governance issues are now emerging in programmable financial infrastructure, particularly as distributed ledgers introduce new data lineage and settlement traceability requirements (see our analysis of programmable finance on DLT).
From Logging to Architectural Traceability
This is not merely a technical logging problem. It is an architectural commitment to traceability by design.
At Data Sense, we approach scalable AI agents through this lens. Autonomy becomes viable only when every action can be mapped, attributed, and reconstructed with the same rigor applied to financial transactions or regulatory submissions. Achieving that standard requires deliberate architecture for identifiers, lineage, and orchestration logging so institutions can understand how an agent reached a decision and how that decision propagated across systems.
Evaluation as Controlled Exposure
Reliability for scalable AI agents cannot be defined solely in terms of task accuracy. It must be evaluated relative to exposure.
An agent assisting with low-impact internal documentation does not carry the same risk density as one updating financial reconciliations or generating regulatory disclosures.
Risk-Weighted Evaluation
Accordingly, evaluation frameworks should incorporate:
- Scenario-based stress testing
- Drift monitoring across time and data shifts
- Quantified error tolerance thresholds
- Impact-weighted performance metrics
These disciplines mirror established model risk management practices. The difference is that agents operate across broader surfaces — data, tools, workflows — requiring integrated oversight rather than isolated validation.
Continuous Measurement and Operational Control
Continuous measurement transforms autonomy from a speculative capability into a managed exposure. Measurement alone, however, cannot guarantee control if agent architectures remain opaque or tightly coupled. Governance also requires systems to be designed in ways that limit the scope and propagation of failures.
Architectural Containment and Modular Design
Why Monolithic Agents Concentrate Risk
A common implementation error is to centralize broad authority within a single, generalized agent. From a systems perspective, this concentrates risk and obscures accountability.
Domain-Scoped Agents and Containment
A modular approach based on domain-scoped agents with clearly bounded responsibilities supports containment. Failures remain localized, oversight becomes more tractable, and decision rights can be attributed more clearly to individual agents.
An orchestration layer can coordinate these components, but containment remains the governing principle. Autonomy scales more safely when scope is explicit and identifiers remain persistent across systems.
Aligning Agent Architecture with Risk Engineering Principles
This design philosophy aligns with long-established risk engineering principles: segregation of duties, least-privilege access, and transaction-level auditability.
Institutional Readiness Across Sectors
Financial Services: Traceability and Regulatory Defensibility
In financial services, scalable AI agents increasingly intersect with derivatives reporting, reconciliation processes, and capital-sensitive workflows. Here, traceability is inseparable from regulatory defensibility. Without standardized identifiers and auditable data pipelines, agentic systems risk amplifying fragmentation rather than resolving it.
Retail and Manufacturing: Operational Provenance
In retail and manufacturing, the surfaces differ, but the logic is consistent. Customer data, supply chain inputs, and operational diagnostics all require clear provenance and accountability chains if autonomy is to be deployed responsibly.
Governance as Institutional Architecture
Across sectors, the organizations progressing beyond pilots share a common trait: they treat governance as architecture rather than documentation.
Governance as the Foundation for Scalable AI Agents
The pursuit of scalable AI agents is, at its core, a question of institutional design.
Autonomy Magnifies Data Architecture
Autonomous capability magnifies the strengths and weaknesses of the underlying data and control environment. Where lineage is fragmented and accountability diffuse, agents increase complexity. Where identifiers are standardized and traceability embedded, agents create leverage.
Traceability as the Enabler of Scalable AI Agents
At Data Sense, our focus is on aligning data architecture, standardized identifiers, and regulatory reporting frameworks so that autonomy can be integrated without eroding institutional resilience. For organizations operating in environments shaped by systemic risk, capital regulation, and cross-border reporting obligations, scalable AI agents become viable only when traceability is engineered from the outset.
The next phase of enterprise AI will not be defined by model benchmarks but by governance architecture. Institutions that can trace, attribute, and supervise autonomous systems will be able to scale them with confidence; those that cannot will keep them confined to experimental environments. The practical question is no longer whether AI agents can perform complex tasks. It is whether institutions have built the governance architecture required to supervise them.
Subscribe to Data Sense
Data Sense publishes research and practical frameworks on scalable AI agents, governance architecture, and institutional traceability.
Our work focuses on how organizations integrate autonomous systems into regulated environments while maintaining auditability, operational control, and clear accountability across data pipelines and decision systems.
Join our community for ongoing analysis on AI-driven data infrastructure, financial analytics, and governance frameworks shaping enterprise adoption.
