
A Data-First View of Model Risk and Monitoring
In financial risk management, debates about Bayesian versus frequentist inference are often framed as methodological or philosophical. In practice, the choice is far more pragmatic: it is primarily a data problem.
Model risk, drift, and operational risk live upstream of market, credit, and liquidity models. They are shaped less by elegant theory and more by the realities of data volume, stability, and interpretability. This is where the distinction between frequentist and Bayesian inference becomes operationally meaningful.
Frequentist inference: stable data, fixed rules
Frequentist methods work best when data are abundant, repeatable, and relatively stationary. They answer questions of the form: “If nothing has changed, how unlikely is this observation?”
In financial risk monitoring, frequentist inference is typically applied when:
- Baselines are well defined Historical distributions exist and are trusted (e.g., model errors, processing volumes, control failures).
- Monitoring rules must be deterministic Thresholds, control limits, and hypothesis tests can be specified in advance and applied consistently.
- Governance and auditability dominate Decisions must be reproducible, explainable, and defensible without subjective inputs.
From a data perspective, frequentist methods assume:
- Enough observations to estimate variability reliably
- Limited structural change over the monitoring horizon
- Clear separation between “design time” and “run time”
This makes them ideal for standardized model performance checks, drift indicators, and operational KRIs that regulators expect to see applied uniformly.
Bayesian inference: sparse, evolving, or contextual data
Bayesian inference becomes attractive when those assumptions break down. Instead of asking whether an observation violates a fixed rule, Bayesian methods ask: “Given what we know so far, how has our belief about risk changed?”
In model risk and operational risk, this aligns closely with the data reality:
- Signals are sparse or delayed Severe model failures and control breakdowns are rare, but consequential.
- Distributions evolve Data pipelines change, business usage shifts, and regimes move faster than historical baselines can keep up.
- Context matters Expert judgment, model limitations, and known weaknesses are often as informative as the data itself.
Bayesian methods allow these factors to be combined explicitly, producing probabilistic risk estimates with uncertainty attached, rather than binary pass/fail outcomes.
A simple data-centric monitoring pipeline
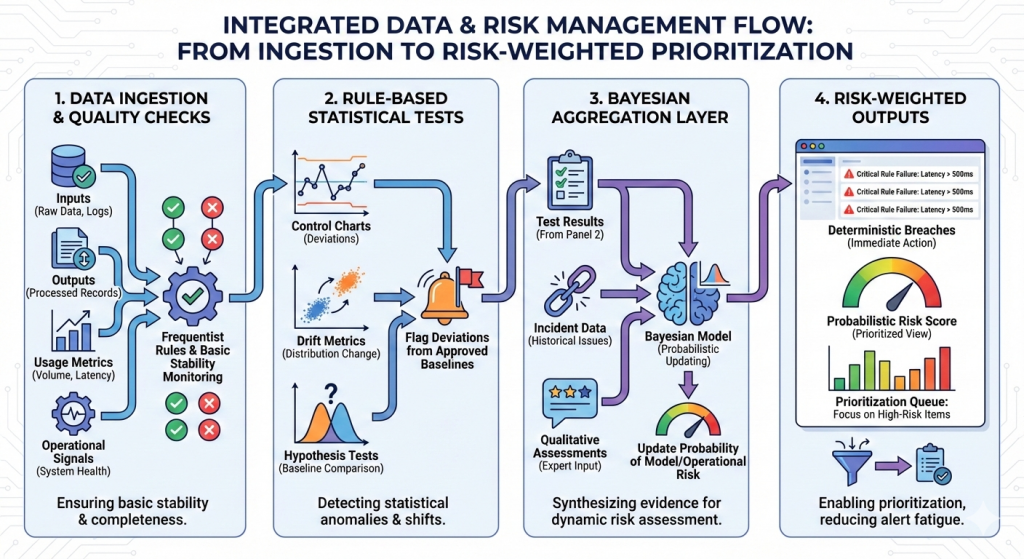
A practical way institutions blend both approaches looks like this:
- Data ingestion and quality checks: Inputs, outputs, usage metrics, and operational signals are monitored with frequentist rules to ensure basic stability and completeness.
- Rule-based statistical tests: Control charts, drift metrics, and hypothesis tests flag deviations from approved baselines.
- Bayesian aggregation layer: Test results, incident data, and qualitative assessments feed into a Bayesian model that updates the probability of model or operational risk.
- Risk-weighted outputs: Dashboards show both deterministic breaches and probabilistic risk scores, enabling prioritization rather than alert fatigue.
The key point: frequentist methods provide oversight of the data; Bayesian methods help to interpret what it means when the data is ambiguous.
Regulatory expectations, mapped lightly
Supervisory frameworks (e.g., SR 11-7, ECB TRIM, PRA expectations) implicitly reflect this split:
- They expect frequentist controls for validation, backtesting, and ongoing monitoring because these are easy to demonstrate and replicate.
- They also expect judgment, proportionality, and forward-looking assessment, which Bayesian frameworks naturally support, even if not labeled as such.
Used together, they satisfy both the letter and the spirit of model risk governance.
Why this matters
Viewed through a data lens, the Bayesian versus frequentist inference distinction is less about statistical preference and more about architectural choice. It forces risk teams to be explicit about what their data can and cannot support, how much uncertainty they are willing to surface, and where judgment belongs in automated decision making — particularly when underlying datasets are sparse, sensitive, or structurally limited (as we explored in our work on synthetic data in financial risk).
As GRC platforms increasingly embed AI and adaptive analytics, these choices shape not just how risk is measured, but how systems learn, escalate, and explain decisions over time, turning inference into a core design consideration rather than a downstream modeling detail.
A data-first approach reframes the choice:
- Use frequentist inference where data are stable and governance demands clarity.
- Use Bayesian inference where data are sparse, shifting, or context-dependent.
- Blend them where risk is highest.
How Data Sense Helps

Data Sense works with financial institutions to design data-first risk and GRC architectures that align statistical methods with how data actually behaves in production. We help teams operationalize monitoring frameworks that combine deterministic controls with adaptive, uncertainty-aware analytics, thereby supporting model risk management, drift detection, and operational oversight as platforms evolve toward AI-enabled decision making.
The focus is not on choosing a “better” inference paradigm, but on building data pipelines, controls, and governance workflows that are explainable, auditable, and resilient as risk signals, models, and regulatory expectations change.