
How distributed ledgers reshape settlement data, risk metrics, and privacy controls in financial markets.
TL;DR (for data leaders)
- Interoperability is a data problem first: you want every rail to describe the same payment the same way at the same time.
- Treat finality as a data attribute with clear lifecycle states and SLOs; don’t trigger downstream actions on provisional states.
- Immutability is great for lineage, bad for rectification. This can be solved with append-only corrections, encrypt-then-anchor, and redaction playbooks.
- Use selective disclosure (ZK proofs) and federated learning with local differential privacy to do analytics without over-sharing data.
- Measure what matters: latency to settled/irrevocable, observability lag, atomicity breaches, and data quality conformance.
Introduction: A Data-Centric Look at Programmable Finance on DLT
The rise of programmable finance on DLT is reshaping how financial institutions think about settlement, data governance, privacy, and risk. Unlike earlier blockchain hype, today’s experiments focus on the data foundations of trust: ensuring interoperability across rails, clear definitions of finality, and privacy-preserving analytics at scale.
Interoperability in Programmable Finance on DLT: Achieving a Single Version of the Truth
Interoperability is the ability for different payment systems, RTGS, instant payments, card networks, and DLTs, to “tell the same story” about a transaction. Without it, each system can produce slightly different records, creating reconciliation noise and risk.
For example, a cross-border payment that flows through multiple rails may be “settled” in one system but still “pending” in another. This misalignment leads to duplicate entries, timing mismatches, and gaps in reporting that obscure real liquidity positions. In high-value markets, that lack of consistency can distort intraday cash management and risk dashboards.
Atomic settlement improves interoperability by synchronizing payments across systems: either all legs of the transaction succeed, or none do. This reduces principal risk and ensures consistency in state. However, atomicity doesn’t fully solve the data alignment problem. Different systems may still use varied schemas, identifiers, and message formats (e.g., ISO 20022 vs proprietary fields), making integration fragile.
To address this, it is necessary to implement and agree upon a common data model (e.g., ISO 20022 fields for who/what/when) and capture a single synchronised receipt when multi-system payments complete.
To envision this, consider a model where a neutral “intermediary” waits for both signatures and then issues one synchronised receipt. That receipt, plus the IDs and timestamps, is what your risk dashboards should ingest.
What to Implement (Data View)
- One canonical payment ID – similar to a Unique Transaction Identifier (UTI) for derivatives contracts – across all rails + a mapping table.
- A lifecycle for each payment: submitted → accepted → reserved → settled → irrevocable.
- Store the synchronised receipt (who signed, when, and a hash) beside the business record to serve as a single source of truth.
Metrics to Monitor
- Cross-rail consistency rate: % of transactions where all systems report the same state within defined time bounds.
- Latency skew: average and max delay between systems updating the same transaction.
- Receipt completeness: % of multi-rail transactions with a synchronised receipt logged.
- Reconciliation effort: time/volume of manual adjustments caused by system misalignment.
These metrics reveal whether interoperability is working in practice. Atomic settlement reduces the biggest risks, but without standardized data structures and consistent receipts, misaligned records will continue to undermine trust.
Settlement Finality in Programmable Finance on DLT: Understanding Payment States
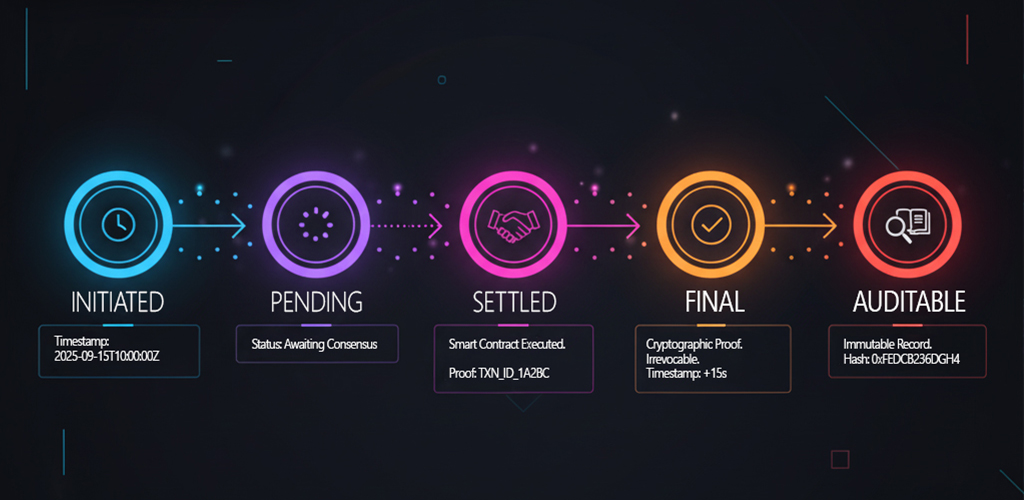
Finality is the moment a payment stops being changeable; before that, treat it as provisional in your data.
For instance, if you book revenue, release collateral, or drop hedges before a payment is finished, you create reconciliation errors and add risk. What risk? Acting before payment finality creates settlement risk where counterparties may fail to deliver, leading to financial statement errors, liquidity gaps, and potential regulatory violations when recorded transactions must be reversed.
Atomic settlement eliminates some but not all risk
Atomic settlement eliminates counterparty risk by removing provisional payment states and ensuring all components of a transaction (payment, asset transfer, collateral release) happen simultaneously and irreversibly. In theory, this removes the timing gaps that could create reconciliation risks as noted above. However, for more complex payments, such as derivatives contracts, reconciliation errors may still occur when oracle pricing data lags behind rapidly changing market conditions, creating windows where settlements execute on economically outdated information.
Given these finality risks, how do you actually implement systems that respect payment states? The key is making finality stages visible in your data architecture.
Different payment rails reach finality on different timelines, and your data should make that visible. Think of it like flight status tracking: scheduled → boarding → airborne → landed. You wouldn’t schedule ground crew off duty based on “scheduled” – they wait for “landed.” Similarly, trigger downstream actions only when payments reach settled or irrevocable status, not on initial acceptance.
The implementation centers on explicit state tracking.
What to Implement (Data View)
- Add a
finality_statecolumn to your payment data with clear stages likeaccepted,settled, andirrevocable, each with timestamps. - Configure downstream jobs – revenue recognition, collateral release, hedge adjustments – to key off these finality states rather than raw ledger events. This prevents the premature actions that create reconciliation errors.
- Monitor the timing between states as service level objectives (SLOs). Track
accepted→settleddurations,settled→irrevocabletransitions, and the lag between actual events and when your systems observe them.
Layered blockchain architectures introduce additional complexity to finality tracking. In systems like the Bitcoin (BTC) Lightning Network or Ethereum (ETH) layer-2 solutions, you now have multiple finality stages: off-chain agreement between parties, channel closure or rollup submission, and final settlement on the base layer.
Adjusting for Off-Chain Updates
Your finality_state column must account for these layers. Consider additional states like channel_updated, channel_closed, rollup_submitted, and on_chain_settled to track these intermediate stages.
Each layer has different timing characteristics and risk profiles. Off-chain finality may happen in milliseconds but carries counterparty risk until base-layer settlement, which could take minutes or hours but provides cryptographic finality. Your SLO monitoring needs to track individual state transitions and also the end-to-end time from initial off-chain agreement to base-layer irrevocability, as this determines your true settlement risk exposure.
Metrics to Monitor
- Settlement latency: average time from accepted → settled.
- Irrevocability lag: average time from settled → irrevocable.
- Observability lag: event time vs when systems observe and act.
- Error reversals: frequency of downstream actions taken before irrevocability that required reversal.
These metrics reveal system health and settlement mechanism performance. For traditional payment rails with provisional states, prolonged settlement times signal when to delay downstream actions. For atomic settlement systems, unusual patterns in settlement success rates or completion times may indicate underlying infrastructure stress or, in the case of derivatives, oracle data lag that could affect settlement accuracy.
Immutability in Programmable Finance on DLT: Permanent Records and Flexible Corrections
Immutability is the idea that ledger entries cannot be changed. It is both blockchain’s greatest strength and a practical challenge in finance. It ensures integrity, but in real-world operations, errors, sanctions, and privacy requirements demand adjustments.
For example, a mistaken payment entry left on an immutable ledger could inflate a firm’s reported exposures if not corrected. Similarly, privacy regulations may require redaction or key revocation that conflicts with the “write once, never change” philosophy.
Atomic settlement enforces immutability at the transaction level, once committed, the transfer is final. This provides assurance but also amplifies the consequences of incorrect inputs (such as a misrouted transfer or outdated oracle data). While atomic settlement prevents tampering, it cannot prevent human or system errors before the transaction reaches the ledger.
The aforementioned Lightning Network and ETH‘s layer-2 systems address this tension through off-chain state management. The Lightning Network allows users to make transactions off-chain without the need for block confirmation on the blockchain, creating a buffer zone where errors can be corrected through subsequent channel updates before final settlement. Similarly, Ethereum’s rollups and state channels enable multiple state updates off-chain with only periodic commits to the main chain. This layered immutability approach preserves base-layer security while providing the operational flexibility financial institutions need for error correction and regulatory compliance.
What to Implement (Data View)
- Use append-only corrections: record a
correction_eventthat points to the original transaction and marks it “superseded,” rather than deleting or altering history.- In layered systems, distinguish between off-chain corrections (channel updates, rollup state changes) and on-chain corrections that require base-layer events.
- Apply encrypt-then-anchor design: sensitive personal or contractual data is encrypted off-chain, while the ledger stores only references or commitments.
- In Lightning or layer-2 systems, this becomes a two-tier approach;
- Sensitive data stays in off-chain channels with only state commitments anchored to the base layer.
- Redaction becomes a matter of revoking keys at the appropriate layer.
- In Lightning or layer-2 systems, this becomes a two-tier approach;
- For contract or schema upgrades, emit migration events that show lineage across versions and layers so downstream analytics can reconcile old and new states.
- Track whether upgrades happen at the off-chain logic level, base-layer contract level, or both.
Metrics to Monitor
- Correction frequency: % of transactions superseded by corrections, segmented by cause and layer (off-chain vs on-chain corrections have different implications and costs).
- Correction latency: average time between error detection and correction event logged, broken down by correction layer.*
- Supersede traceability: % of corrections properly linked to their original records across all layers of the system.
- Layer coherence: % of off-chain corrections that successfully propagate to base-layer records when required.
- Upgrade lineage coverage: % of contracts or schema changes with full migration event history, including cross-layer upgrade coordination.
*Off-chain corrections are typically faster and cheaper but carry counterparty risk until the channel or layer-2 system eventually settles to the base layer, while on-chain corrections are slower and more expensive but provide immediate cryptographic finality.
These metrics measure how well a system handles the unavoidable need for corrections and updates without breaking the integrity of the ledger. They track how often corrections are made, how quickly they’re logged, and whether each change is transparently linked back to the original record.
Scalability and Data Governance in Programmable Finance on DLT

Scalability is about whether your infrastructure can keep up with transaction volume without breaking the visibility you need for risk controls. Even fast ledgers generate enormous data exhaust… every transaction, state change, and proof object must be stored, indexed, and replayable for audits.
The Federal Reserve Testing and the BIS Findings
Today’s high-volume payment systems process millions of transactions per second, which can overwhelm downstream monitoring and reconciliation systems. For example, research prototypes such as the Federal Reserve’s Project Hamilton demonstrated throughput of 1.7 million transactions per second in testing, but the Fed noted that achieving this scalability required trade-offs with privacy and auditability.
The BIS has emphasized that the scalability challenge is not just raw throughput but ensuring that observability and audit functions scale in parallel with settlement volume. In real-world deployment, if downstream monitoring lags behind actual transaction processing, institutions may act on stale data. Liquidity managers could misjudge intraday positions, or regulators could miss early signs of stress because observability systems choke under load.
Atomic settlement improves efficiency by eliminating intermediate states, but it does not remove data volume. In fact, atomicity can amplify load, since multiple legs (payment, collateral, asset transfer) settle simultaneously and must all be logged with cryptographic proof objects.
What to Implement (Data View)
- Define storage tiers (hot for real-time monitoring, warm for T+1 analytics, cold for archive/audit) and enforce retention policies.
- Hot for real-time monitoring, Warm for T+1 analytics, Cold for archive/audit
- Support deterministic replay: ensure partial orders and proof objects can reconstruct the ledger state exactly if reprocessing is needed.
- Implement back-pressure management in streaming pipelines so monitoring systems control the flow of data instead of failing during bursts.
Metrics to Monitor
- Throughput capacity: max sustained transactions per second ingested into hot storage.
- Replay success rate: % of replayed batches that exactly match historical states.
- Observability lag: delay between event occurrence and its visibility in risk dashboards.
- Back-pressure events: frequency and duration of dropped/delayed events due to load.
These metrics focus on whether data pipelines and monitoring can keep pace with transaction volume. They capture throughput, replay accuracy, and lag between when a payment happens and when it’s visible to risk dashboards, showing how resilient the system is under stress.
Scalability in programmable finance on DLT has real data trade-offs. The Federal Reserves Project Hamilton showed, from a data-risk perspective, that faster systems often give you less observability and more complex replay requirements.
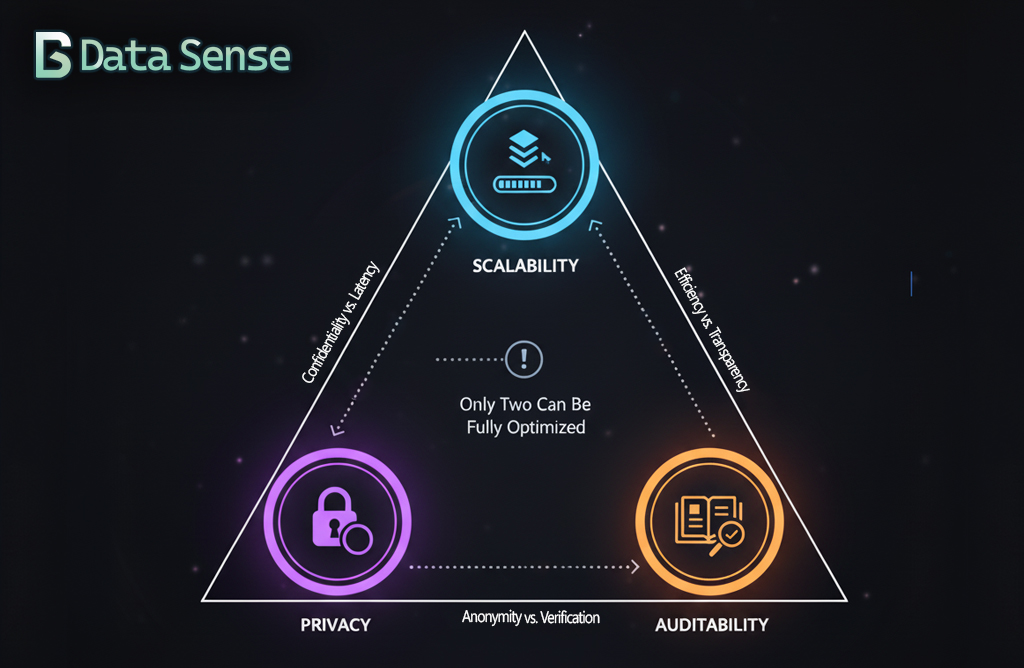
That same tension extends into privacy. Increasing privacy protections can reduce auditability, while designs optimised for audit trails often expose more transaction detail.
Privacy-Preserving Analytics: Balancing Compliance and Confidentiality
Privacy is one of the sharpest paradoxes in DLT systems. Ledgers are transparent by design, but finance requires strict confidentiality. BIS research highlights this trade-off clearly: efficiency, privacy, and auditability cannot all be maximised at once, and institutions must decide which risks to prioritise.
The challenge is allowing institutions and regulators to verify facts about transactions without exposing sensitive data.
For instance, banks may need to demonstrate compliance with AML thresholds across thousands of transactions without disclosing customer-level details. Without privacy-preserving methods, institutions risk over-sharing data, violating GDPR or local privacy laws.
Emerging tools aim to soften this trade-off. Zero-knowledge proofs (ZKPs) allow institutions to prove compliance with specific rules without exposing underlying transaction details, preserving privacy while still offering regulators the evidence they need. In parallel, federated learning with local differential privacy lets banks and supervisors train shared risk models without pooling raw data, reducing confidentiality risks while still improving systemic visibility.
What to Implement (Data View)
- Zero-Knowledge Proofs (ZKPs) allow for selective disclosure, e.g., prove “all transactions under €10,000” without revealing amounts or counterparties.
- Federated Learning (FL) to train fraud or risk models collaboratively without moving raw data;
- Add Local Differential Privacy (LDP) to prevent leakage.
- Proof receipts to log ZK circuit versions, parameters, and proof hashes alongside transactions so auditors can verify claims later.
Metrics to Monitor
- Proof verification rate: % of proofs successfully validated across circuits.
- Privacy budget (ε): track cumulative differential privacy cost spent across analyses.
- Break-glass events: number of times raw data access was requested, with reason and approvers logged.
- Federated model drift: accuracy/variance of FL models across institutions to ensure privacy methods don’t degrade utility.
These metrics focus on whether confidentiality controls hold up as systems scale. They capture how often zero-knowledge proofs verify successfully, how much of the available privacy budget is consumed in federated learning, and how frequently “break-glass” access is used. Together, they show whether stronger privacy comes at the expense of transparency, or if institutions are balancing confidentiality and auditability effectively under load.
Together, these approaches don’t eliminate the trade-offs, but they rebalance them making it possible to scale while keeping both privacy and auditability within acceptable bounds.
What to Measure (KPIs, SLOs, and Controls)
Data SLOs (per rail & cross-rail)
- T_settle:
accepted → settled - T_irrev:
settled → irrevocable - T_observe: event time → observability in monitoring/lake
- Miss/Dup rate: % late, dropped, or duplicate events (by lifecycle state)
- Atomicity breach attempts: count & % of attempted non-atomic completions detected/blocked by the “conductor”
Data Quality & Lineage
- Completeness & conformance: ISO 20022 field fill-rates, code-list validity, reference-data drift.
- Consistency: cross-rail state parity (conductor receipt ↔ RTGS booking ↔ asset-ledger transfer).
- Lineage depth: hops from source to report, with verifiable proof chains.
Privacy & Access
- ZK verification success rate (by rule/circuit).
- ε (epsilon) spent for LDP/FL.
- Break-glass audits (count, reason, approvers).
Market Data Dependencies
- Oracle variance (vs median of sources).
- Time-at-risk when feeds degrade.
- MEV exposure (mempool residency, inclusion delay).
A Pragmatic Data Roadmap (12–18 months)
flowchart TB
subgraph row1 [" "]
direction LR
A1["`**Step 1: Schema and catalog first**
(2-3 months)
ISO 20022 schema, schema registry, reference data`"]
A2["`**Step 2: Synchronised receipts as data**
(3-4 months)
Emit signed receipts from conductor, store with events`"]
A3["`**Step 3: Finality states and idempotency**
(2-3 months)
Lifecycle states accepted to settled to irrevocable, idempotent ingestion`"]
A4["`**Step 4: Privacy by design pilots**
(4-6 months)
ZK attestations, federated learning with LDP, log proofs and budgets`"]
A1 --> A2
A2 --> A3
A3 --> A4
end
subgraph row2 [" "]
direction LR
A6["`**Step 6: Oracle and MEV telemetry**
(3-4 months)
Variance bands, feed SLAs, circuit breakers, mempool metrics`"]
A5["`**Step 5: Observability and SLOs**
(2-3 months)
SLIs and SLOs for T_settle T_irrev T_observe, structured logs`"]
A5 --> A6
end
subgraph row3 [" "]
A7["`**Step 7: Retention and deterministic replay**
(2-3 months)
Tiered storage, deterministic rebuild, recovery tests`"]
end
row1 ~~~ row2
row2 ~~~ row3
classDef ds fill:#CFEFE3,stroke:#2F7D6A,color:#0F172A,stroke-width:1.5px
class A1,A2,A3,A4,A5,A6,A7 dsConclusion: Data is the Control Surface
The future of programmable finance on DLT will be dictated by how well institutions govern data, measure risk, and balance privacy with transparency.
Treating interoperability as a shared data language and lifecycle; treating immutability as a default you override, albeit carefully with governed, auditable corrections. The firms that operationalise these data practices will get real risk reduction and faster reconciliation, not just faster blocks and transaction times.
The next step for institutions isn’t adopting every new protocol, it’s mapping their own data path forward. Which trade-offs matter most: scalability, privacy, or auditability? By benchmarking the right metrics today, firms can decide where programmable finance on DLT adds value and where traditional rails remain fit for purpose.