
In our previous article, we argued that governance is the prerequisite for scalable AI systems. As organizations move from experimentation to deploying autonomous agents, governance can no longer rely on human oversight alone. Policies, controls, and access rules must be interpretable by machines.
For this to work, AI systems require institutional traceability: the ability to understand where information originated, how it was transformed, and what policies govern its use. Metadata is the layer that makes those controls executable.
In order for AI agents to operate safely and reliably, metadata must evolve from human-oriented documentation into machine-readable infrastructure that encodes provenance, purpose, permissions, and lineage directly into the data ecosystem.
This article continues our exploration of the architectural foundations required for scalable AI systems, focusing on the role metadata plays in making governance executable by machines.
The Difference Between Metadata for AI Agents and Metadata for Humans.
The distinction between human-oriented metadata and machine-operational metadata becomes clearer when viewed as two different architectural models.
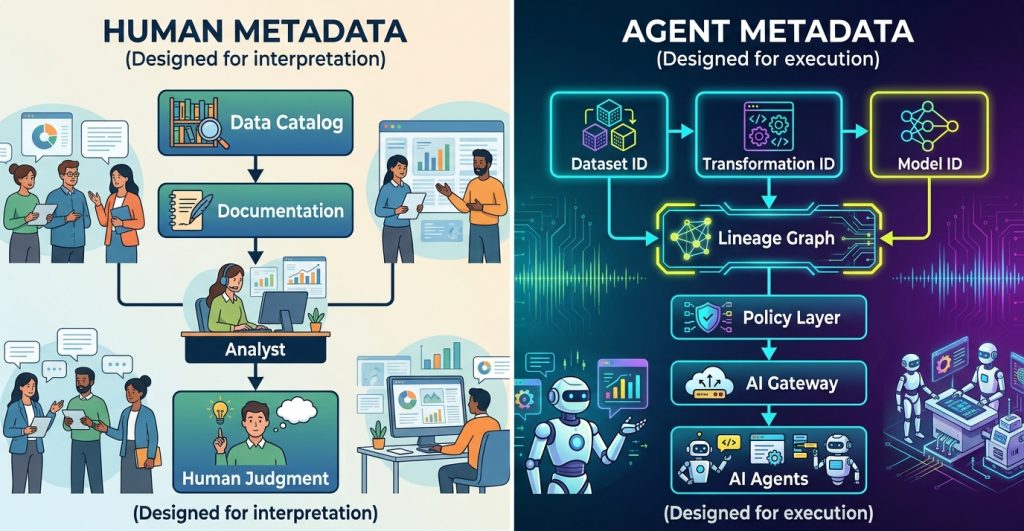
Traditional metadata systems were designed to help people interpret data. AI systems require metadata that machines can execute.
Human Metadata: Designed for Interpretation
Traditional metadata systems were built for people.
Data catalogs, documentation pages, and semantic descriptions helped analysts understand datasets: what they contain, who owns them, and how they should be used.
Metadata acted as institutional memory, allowing humans to navigate increasingly complex data environments through documentation.
Typical metadata answered questions such as:
- What does this dataset represent?
- Who owns it?
- When was it last updated?
- What business definitions apply?
A human analyst encountering a dataset might search the catalog, read the description, inspect lineage diagrams, and then decide whether the data is trustworthy or appropriate for a particular task.
This workflow works because humans can resolve ambiguity and apply judgment.
AI agents cannot.
Agents do not read documentation or infer context. They require metadata that is structured, explicit, and interpretable by machines.
AI Agent Metadata: Designed for Execution
AI agents interact with data differently than humans.
Instead of interpreting context through documentation, they require metadata that directly encodes the rules governing data usage. Metadata becomes not just descriptive context, but operational instructions.
For an AI agent, metadata must answer questions such as:
- Where did this data originate?
- What transformations produced it?
- What is the allowed purpose of use?
- What models or processes generated it?
- What level of trust or quality does it have?
Without these signals embedded into the data infrastructure, agents cannot safely make decisions about which information to use or how to use it.
This is why machine-readable metadata becomes a prerequisite for governed AI systems. It allows governance policies to be enforced automatically rather than relying on manual interpretation.
Metadata Infrastructure for AI Systems
For metadata to become operational for AI systems, it must be supported by infrastructure that exposes provenance, policy, and evaluation signals in machine-readable form.
Identification and Lineage as the Foundation
For metadata to become operational, datasets and transformations must have stable identifiers.
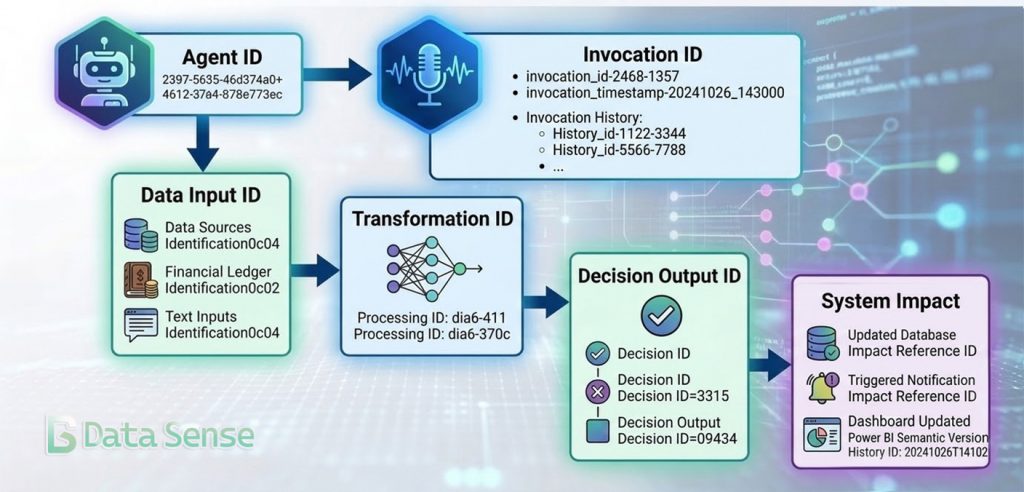
Every component of the data ecosystem requires a traceable identity:
- dataset identifiers
- transformation identifiers
- model identifiers
- policy identifiers
These identities allow systems to construct lineage graphs that map how information moves through an organization.
This type of institutional traceability is increasingly important as organizations move toward automated decision systems.
When an AI agent queries data, it can reconstruct the full provenance chain—where the data originated, how it was transformed, and which policies apply.
Instead of relying on documentation, the agent can programmatically determine whether a dataset is approved for a particular use case.
This turns lineage into something more than documentation. It becomes the backbone of automated governance.
Semantic Layers and Data Catalogs as Agent Infrastructure
Modern data platforms are beginning to reflect this shift.
Research published by the National Bureau of Economic Research found that organizations using semantic layers and data catalogs were able to deploy roughly ten times more AI use cases than firms without them.
The reason is structural.
Semantic layers standardize definitions across an organization. Data catalogs establish ownership, classification, and governance policies. When these elements are machine-readable, AI systems can interact with data in a consistent and controlled way.
Platforms such as Unity Catalog illustrate how metadata is evolving from documentation into governance infrastructure by embedding:
- access control policies
- dataset ownership
- lineage tracking
- usage governance
directly into the data platform.
In this architecture, metadata becomes the control surface for both data and AI systems.
Agent Evaluation as Governance Metadata
Metadata is also required to evaluate the behavior of AI agents themselves.
Unlike traditional software systems, AI agents operate probabilistically. Their performance must be continuously monitored and assessed across a variety of tasks.
One way to conceptualize this is as a grade point average for AI agents.
Rather than relying on a single metric, agents accumulate performance signals across different dimensions:
- response accuracy
- hallucination frequency
- policy compliance
- task completion rates
- latency and cost efficiency
These signals become evaluation metadata attached to the agent’s identity.
Governance systems can then use these signals to enforce automated policies such as: restricting low-performing agents from critical workflows, requiring human review for certain tasks, and promoting high-performing agents to higher levels of autonomy.
Evaluation metrics therefore become part of the governance architecture rather than merely operational monitoring.
AI Gateways and the Enforcement Layer
If metadata defines the rules governing AI systems, something must enforce them.
This is the role of the AI gateway.
An AI gateway sits between applications and models, acting as a centralized control layer for model interactions.
It can enforce policies such as:
- model access permissions
- rate limits and cost controls
- request logging and audit trails
- dataset access policies
Rather than allowing every application to call models directly, the gateway becomes the enforcement mechanism for AI governance.
Combined with machine-readable metadata, gateways allow organizations to implement automated safeguards such as:
- preventing agents from accessing restricted datasets
- routing requests only to approved models
- enforcing budget limits for model usage.
In effect, metadata provides the knowledge about what is allowed, while the gateway ensures those rules are applied consistently.
From Documentation to Infrastructure
The transition from human-readable documentation to machine-readable metadata is one of the most important architectural shifts in the age of AI agents. Governance, lineage, and policy enforcement can no longer exist only in documentation—they must be embedded directly into the data infrastructure.
In future articles, we will explore how these metadata layers connect with identity systems, policy engines, and AI control planes to form the operational backbone of governed AI systems.
As part of this exploration, we are also experimenting with semantic-layer approaches designed to expose machine-readable metadata directly to AI agents, an area that may prove foundational for governed AI architectures.
Series: The Architecture of Governed AI Systems
- Governance is the Precondition for Scalable AI Agents
- Metadata for AI Agents vs Human Metadata
- Identity for AI Systems: The Missing Layer of AI Governance (coming next)
Follow the Series
We are continuing to explore the architecture required for governed AI systems. Upcoming articles will cover identity infrastructure, policy engines, and AI control planes.
Subscribe to the Data Sense newsletter to receive updates when the next article is published.
